How I Keep the AI Bill Down & the Output Sharp
Keeping the context low and the cache high.
People ask how I keep the AI bill down and the output sharp at the same time, as if those pull against each other. They mostly don’t, and this note is about why.
Cost of a prompt with loaded context
A model reasons over whatever you put in front of it. The more you pile in, the worse it reasons over all of it. Chroma tested 18 frontier models on this last year and every one degraded as input grew, gradually, well before the window was full. Extra tokens also cost money, obviously. So the same habit takes care of both problems: I don’t try to use fewer tokens, I try to be picky about which tokens the model sees, every turn.
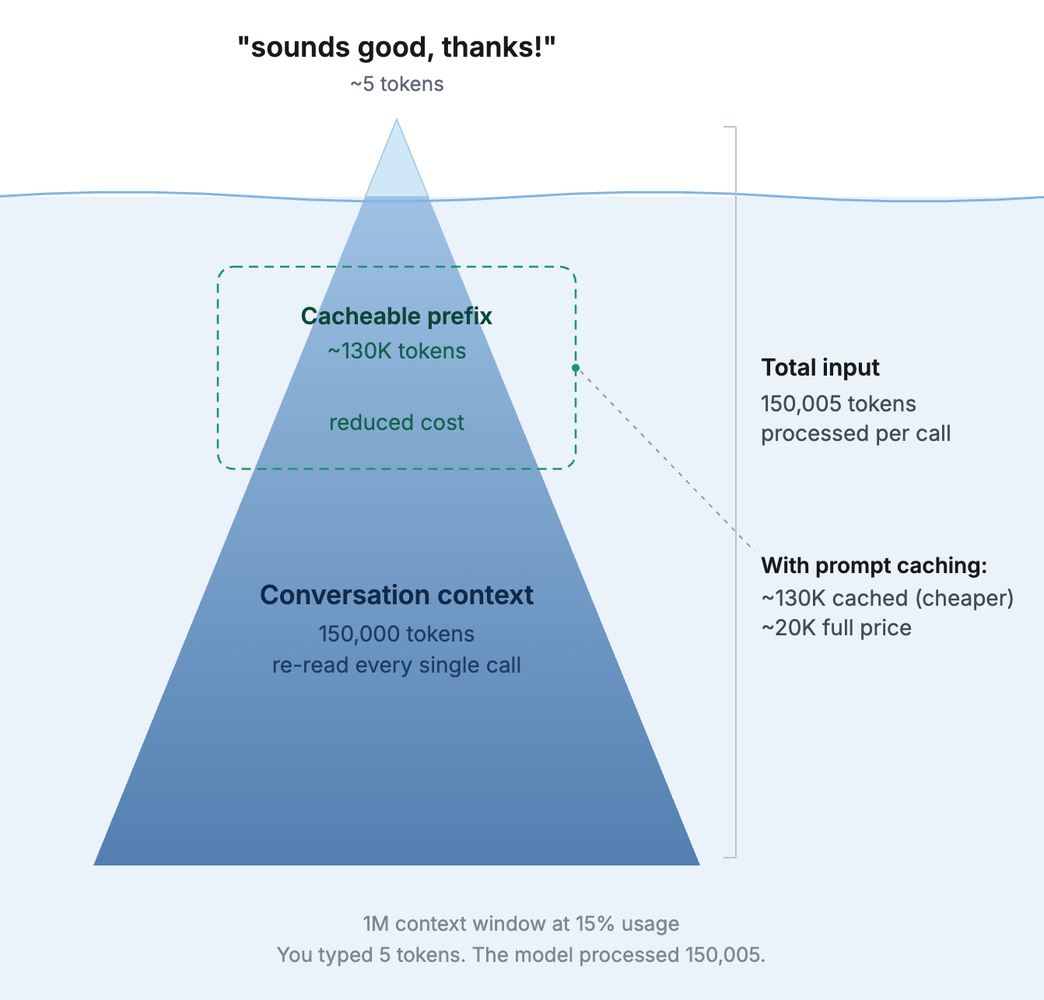
The shift for me was to stop thinking of the context window as a container I’m filling and treat it as the material the model works with. The wrong 100k tokens produce confident nonsense. The right 8k can produce something sharp on the first try, at 1/12th of the price.
What my statusline looks like

This is how I’ve configured my status line. Project folder, git branch, model, effort, estimated cost so far this session, cost of current turn, and the session limits are on the left. Context window and cache on the right. Those two numbers on the right do most of the work: how full the window is, and how much of it came back from cache. You can grab my statusline from this gist.
Everything following is about keeping the context low and the cache high.
One thing worth knowing: the model can’t set anything aside. Whatever data you load competes for attention, so if you dump the whole codebase in, the one file that matters gets one vote out of 200. And the worst filler isn’t random noise, it’s the stuff that looks relevant but isn’t. The adjacent code, previous abandoned approach, brainstorming artefacts, the three tries that didn’t work and similar cruft.
Load only the slice you need
I convert the requirements document into a structured JSON contract and keep it in the repo. It holds the actors, the entities they interact with, user journeys, business rules, constraints, and an open questions list for the ambiguities. I call it the intent model, and it has its own note.
A rule in the intent model looks like this:
{
"rule": "unverified_users_can_draft_but_not_send",
"applies_to": ["compose", "outbox"],
"on_violation": "show_verify_prompt"
}
One entry, and a whole class of edge cases the model doesn’t have to guess or grep.
JSON instead of prose for two reasons. Prose is ambiguous, and writing the contract as JSON forces me to resolve that before the model ever sees it. Also, Anthropic found the same thing building harnesses for long-running agents: the model is less likely to inappropriately change or overwrite a JSON file than a markdown one, so the contract generally survives the model’s ‘helpful’ edits.
On a real, large/complex SaaS project this is never one file. One module per domain, a shared core, plus interaction patterns:
intent/
├─ shared.json loaded every session
├─ auth.json
├─ compose.json
├─ calendar.json
└─ patterns.json interaction patterns
# sign-up screen loads : shared.json + auth.json + patterns.json
# it skips : compose.json, calendar.json
(rules that almost apply, but doesn't)
The skipped modules wouldn’t help if included. They’ll just dilute the context and distract it with rules that almost apply.
Better yet, let the model fetch its own slice. It can grep for the two files it needs. I don’t have to pre-load everything I guessed it might want.
Write the durable stuff down once
Anything true across sessions goes in a file the session reads at startup. Anything that holds true only for this task stays in the conversation.
The most wasteful tokens I’ve spent were on re-explaining the project every session. All of that now lives in CLAUDE.md, since I work in Claude Code (other tools read AGENTS.md or their own equivalent):
CLAUDE.md stack, conventions, structure, decisions behind them
PROGRESS.md "where we are", one paragraph, pinned to the top
DECISIONS.md one-liners, answers itself before it's asked
Instructions that only matter sometimes go into skill files that load on demand. The model reads the presentation instructions when it’s building a presentation, and never otherwise.
Lazar Jovanovic builds products with AI for a living, and on Lenny’s podcast he put a number on what skipping the files costs. Without them, the model “is going to consume 80% of the token allocation on reading to get clarity, leaving only the final 20% for thinking and executing.” His files are PRDs and a tasks.md rather than JSON, and his agents read them before every prompt. Same bet: pay once, in a file, instead of every turn, in the chat.
Caching makes this cheaper than it looks

Cached input tokens cost about 1/10th of fresh ones, and what gets cached is the stable front of your context. So the files listed above pay for themselves. That CACHE reading in the status bar, 96% HIT, is exactly this: the stable front being read back cheap.
If CLAUDE.md and the intent modules sit at the front and don’t churn, every turn after the first turn reads them at a heavy discount. On the contrary, a context that keeps mutating breaks the cache and pays full price each time.
Put rules in tooling, never in the conversation
A lot of what people re-explain every session is rules: don’t hardcode colors, every string goes through the translation layer, no raw fetch calls. I stopped explaining these. They’re ESLint errors now.
$ git commit
› running verify...
✖ raw hex color, use a design token no-hardcoded-color
✖ untranslated string literal i18n/no-raw-string
✖ direct fetch(), use the api client no-raw-fetch
3 errors. commit blocked.
A rule in the linter is context I never have to spend again, and it can’t get diluted by whatever else is in the window. Schemas get verified against checked-in fixtures, and a verify script gates every commit, so most bad output gets caught by the tooling before I even review it.
Fiona Fung, who manages the Claude Code and Cowork teams at Anthropic, calls verification the new bottleneck. Engineers there ship about eight times the code they did a year ago, and no human reviews their way through that volume. The tooling has to make the first pass.
Michael Truell of Cursor advises against telling the model everything in one go. “Chop things up into bits,” be specific about each, review as you go. It’s good prompting advice, and rules are the one thing I’d push a step further: a rule that can be a lint error doesn’t need to be prompted at all, in bits or otherwise.
Push the record to disk
Long sessions degrade, and not because the model gets tired. The window fills with the history of the work: dead ends, the failed iterations, reference files, screenshots, tool calls. None of these helps the next turn, and all of it is going to be weighed.
So I write memory to disk as I go. Commit often. A post-commit hook drops a stub for each meaningful commit, and those drain into a dated build log. Open questions go into open_questions[] in my intent model, instead of riding along in the chat. Once something is written down, I let it leave the context window.
Related: Check what loads before you send a prompt. Every connected MCP server puts its full tool schema into the window at startup, whether you use it or not. I disable the ones the current project doesn’t need. I’m not smart enough to tinker with the system prompt and system tools. These are Claude Code’s built-in harness and tools and are mostly what makes Claude Code behave like it does. I’ll leave that alone for now.
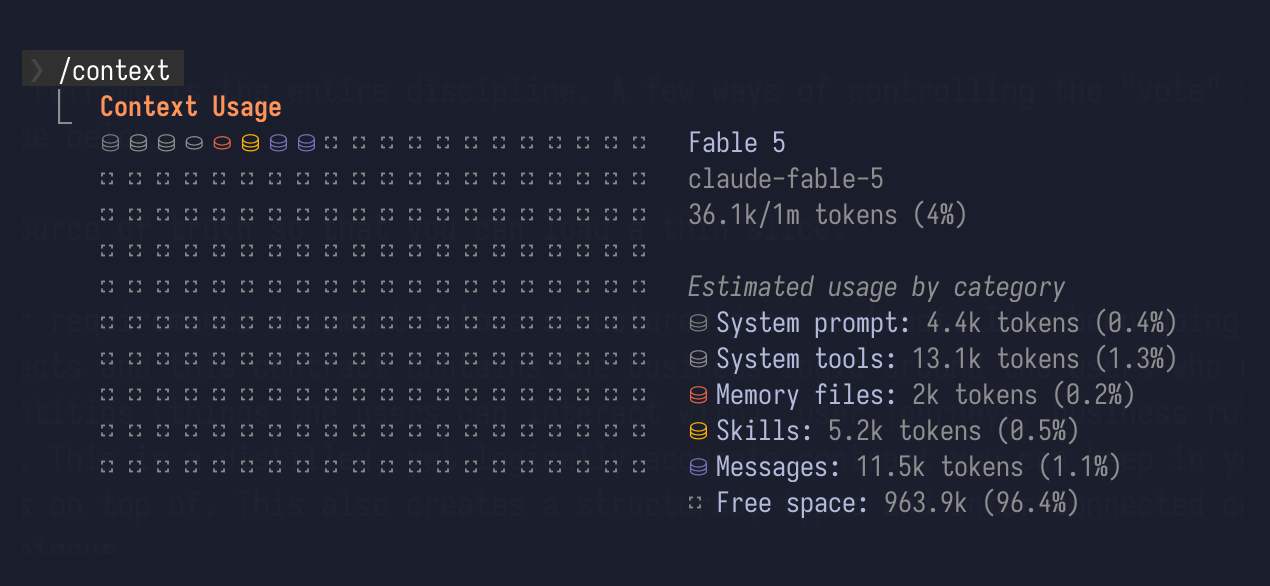
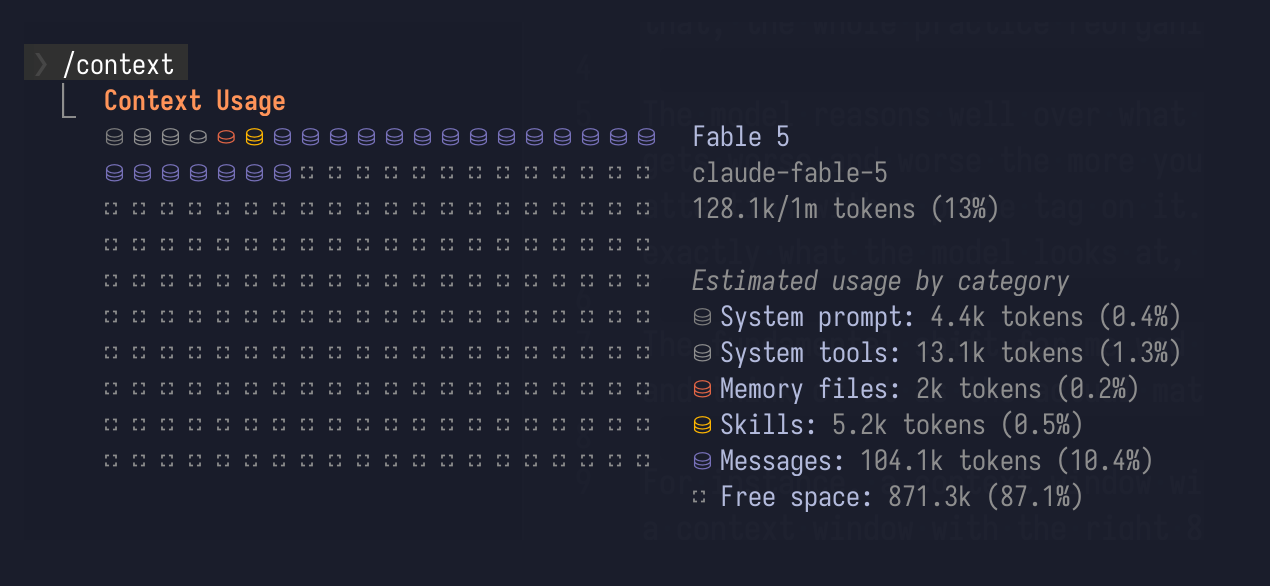
I have ~30 tools connected, zero tokens spent on them until something actually calls one. This is pretty much the whole game: nothing is allowed without purpose in the context window.
Checkpoint before the window sags
My rule: when the window hits about 30% and the work is unfinished, stop.
CONTX ▓▓▓▓▓▓░░░░░░░░░░░░░░ 30% full
↑
around here is the line. update PROGRESS.md, verify,
commit a clean WIP, then reset.
Why 30%? Because a reset is nearly free and a bloated window is expensive. Wrapping up costs context too: the notes, verification and the commit. So if I start that while the window is already cramped, the checkpoint will also get sloppy. 30% is conservative on purpose. I’d rather cut early. You can even cut at 20%, depending on the complexity of the project and your particular use case.
Earlier, I used to protect the investment. I had spent all those tokens loading context, so surely the smart thing was to keep going and get my money’s worth, right? Nope, it wasn’t. A degraded window compounds: Every turn re-reads the whole bloated history and reasons over it a bit worse, right when I’m most tempted to push for one more thing. Caching softens the bill slightly, for the re-reads, but it doesn’t fix the underlying bloat.
Adam Mosseri said something on Lenny’s podcast that stuck with me: “It’s not that hard to build a token incinerator, and that doesn’t create a lot of value.” He was talking about Meta’s AI bill. A degraded window is the desk-sized version of the same machine, tokens going in and a little less coming back every turn.
There’s a middle path, compaction, where the session summarizes itself and continues. I mostly skip it. I believe that a summary written by a degraded session inherits its confusions, and PROGRESS.md is curated by me. The reset and restart takes 30 seconds. Incomplete-but-rigorous beats complete-but-sloppy, and it costs way lesser.
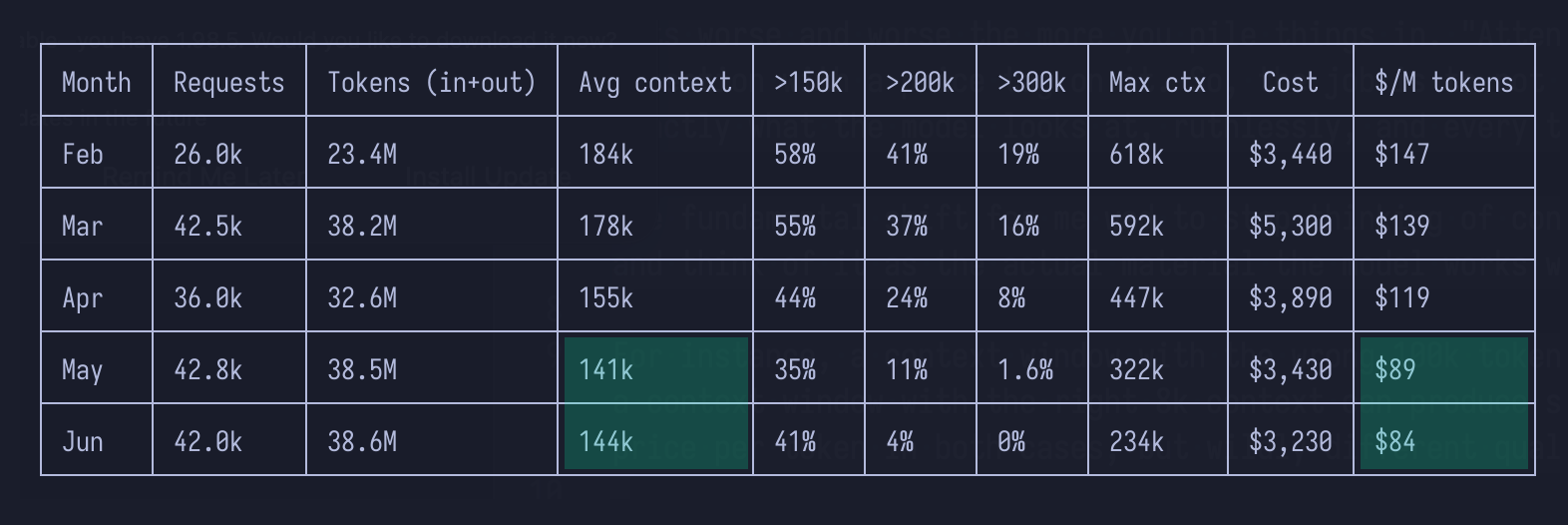
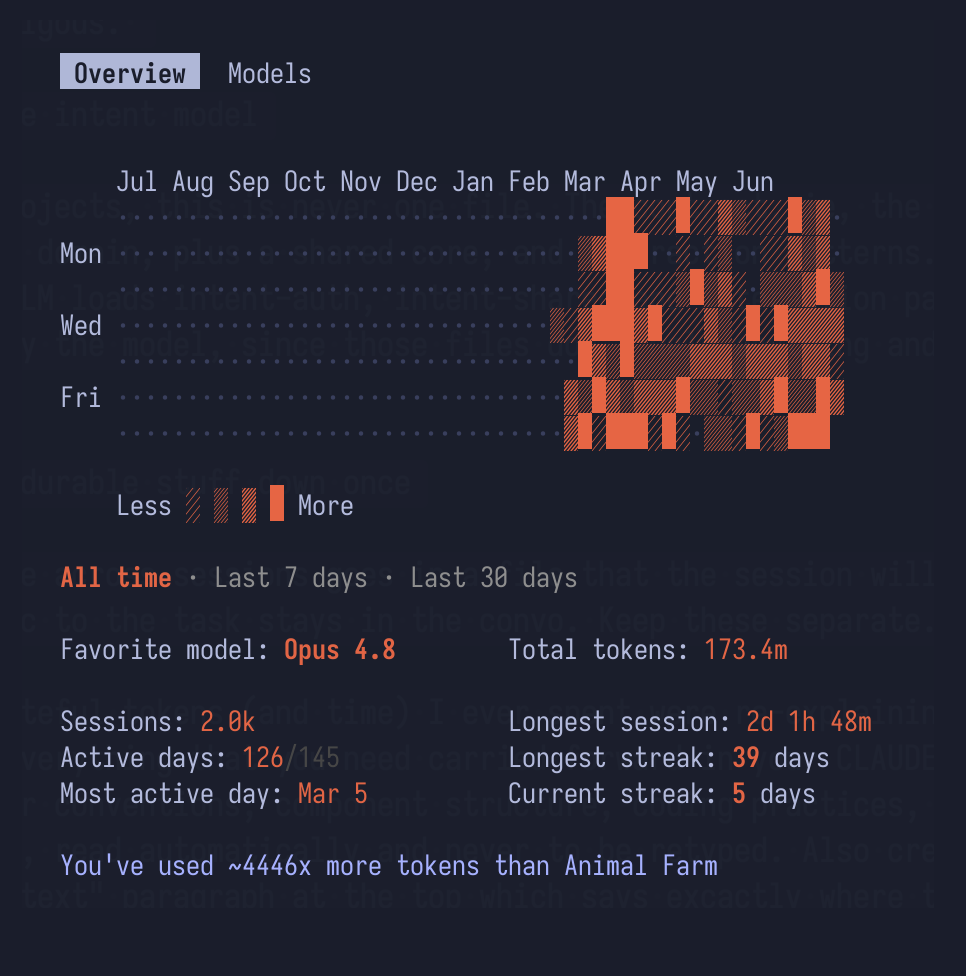
I asked claude to analyze my sessions from this year and what I found actually proved my habit of cutting early resulting in lesser cost per work done.
Give the grunt work to cheaper models
Not every task needs the expensive model. I do the thinking on the big one and hand the mechanical edits to cheaper sub-agents, each with its own slice of context and the exact change it owns. Isolated contexts, run in parallel, and a worker that only sees its slice can’t get distracted by anyone else’s.
Exploration also gets similar treatment. Finding the right slice can fill a window by itself: the greps, the dead-end reads, the six files opened to find the one that mattered. A search agent does that in its own disposable context, and only the conclusion comes back to the main model. Both of these types of workflows are wired up as slash commands and skills.
Two notes for design and front-end folks
Screenshots are some of the most expensive tokens we spend, and we spend them reflexively. Before pasting an image, I check whether a written spec does the job. “8pt grid, 390 by 844, these tokens, this spacing scale” carries most of what a mockup carries at a fraction of the weight. I save images for genuinely visual problems: a rendering bug, a layout that reads wrong, a before-and-after.
Also, a component registry turns out to be a context tool, whether or not you built it as one. When the model composes a screen, it loads the registry index (names, props, usage rules) instead of a dozen component source files. It does for the codebase what the intent model does for the requirements.
What I haven’t solved
The intent model is starting to develop the problem it was built to fix. The shared core grows a little with every domain, and every session loads it. At some point I’ll need to slice the slice, and I don’t have a clean rule for when.
The obvious move is to split it: a shared-lite that loads by default and a shared-full that only loads when a task spans domains. I’ve tried it. The trouble is deciding what’s lite, and that decision moves. A rule that felt peripheral last month is load-bearing this week, and the session that needed it didn’t know to ask for the full core. So the split just relocates the guessing I was trying to get rid of, from “which modules” to “which tier”. If you’ve solved this, I want to hear it.
Not day-one advice
None of this is where I’d tell someone to start. These rules came from a year of watching where the money and the quality actually went, and every one of them is a fix for a problem I’d already felt. Build the whole system before you’ve felt those problems and you’ll optimise for the wrong thing, or worse, tune the context so tightly that the loose, wasteful exploration that shows you what good even looks like never happens. Boris Cherny, who runs Claude Code, is blunt about this: Anthropic hands its engineers near-unlimited tokens, and the cost of an idea gets optimised only after the idea works. Make a mess first. Each habit here is worth more once you know which specific problem it’s solving for you.
The short version
- Load a thin slice
- Keep the rules in tooling
- Write the record to disk as you go
- Checkpoint while there’s still room, then reset
- Give the search and the grunt work to cheaper models
- Keep the reasoning in one place (frontier model)
After a while you can feel the window filling up the way you feel a paragraph running long. A sense that it’s time to cut, checkpoint, and come back clean.